Improving public understanding of probability and risk with special emphasis on its application to the law. Why Bayes theorem and Bayesian networks are needed
I was recently watching a re-run of the classic 1978 Michael Cimino film “The Deer Hunter”. It contains one of the most iconic scenes in cinema history involving a ‘game’ of Russian roulette forcibly played by two American soldiers held captive in Vietnam. Although I have seen the film several times, this scene never seems to lose its impact. As I am currently teaching a new course on Risk Assessment and Decision Making, it also occurred to me that the scene provides a rich source of examples to illustrate core concepts of probability and risk including: probability and odds, basic probability axioms, conditional probability, risk and utility, absolute versus relative risk, event trees, and Bayesian networks.
So, I have written a short paper which hopefully has something of value both for people with no background in probability/statistics and also people who do, but want to find out more:
Researchers at UCL and Birkbeck have published an important study on the benefits of using a Bayesian Network (BN) tool to solve the kinds of complex problems that intelligence analysts are confronted with.
Example of the type of problem considered. Participants had to answer questions such as which group was most likely responsible for the attack based on various details about multiple informant sources and their accuracy
The study provides strong empirical evidence that if you provide basic training to use the BARD tool for constructing BNs then this
improves the ability of individuals to solve complex probabilistic
reasoning problems, compared to a control group receiving only generic
training in probabilistic reasoning.
The full details of the paper (which includes a link to all of the problems and data) are:
Cruz, N., Desai, S. C., Dewitt, S., Hahn, U., Lagnado, D., Liefgreen, A., Phillips, K., Pilditch, T., and Tešić, M. (2020). "Widening Access to Bayesian Problem Solving". Frontiers in Psychology, 11, 660. https://doi.org/10.3389/fpsyg.2020.00660
*I declare an interest here: the BARD tool was developed from the AgenaRisk API.
** Again I declare an interest: I was involved with some of the training
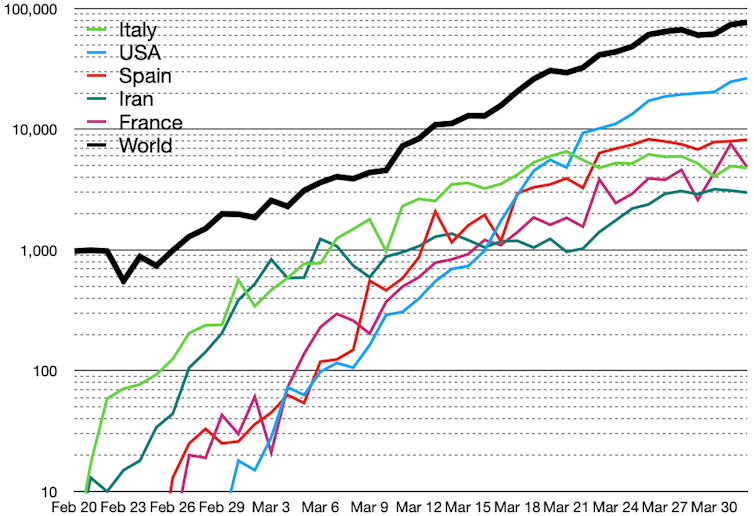
Suppose we wanted to estimate how many car owners there are in the UK and how many of those own a Ford Fiesta, but we only have data on those people who visited Ford car showrooms in the last year. If 10% of the showroom visitors owned a Fiesta, then, because of the bias in the sample, this would certainly overestimate the proportion of Ford Fiesta owners in the country.
Estimating death rates for people with COVID-19 is currently undertaken largely along the same lines. In the UK, for example, almost all testing of COVID-19 is performed on people already hospitalised with COVID-19 symptoms. At the time of writing, there are 29,474 confirmed COVID-19 cases (analogous to car owners visiting a showroom) of whom 2,352 have died (Ford Fiesta owners who visited a showroom). But it misses out all the people with mild or no symptoms.
Read more:
COVID-19 tests: how they work and what's in development
Concluding that the death rate from COVID-19 is on average 8% (2,352 out of 29,474) ignores the many people with COVID-19 who are not hospitalised and have not died (analogous to car owners who did not visit a Ford showroom and who do not own a Ford Fiesta). It is therefore equivalent to making the mistake of concluding that 10% of all car owners own a Fiesta.
There are many prominent examples of this sort of conclusion. The Oxford COVID-19 Evidence Service have undertaken a thorough statistical analysis. They acknowledge potential selection bias, and add confidence intervals showing how big the error may be for the (potentially highly misleading) proportion of deaths among confirmed COVID-19 patients.
They note various factors that can result in wide national differences – for example the UK’s 8% (mean) “death rate” is very high compared to Germany’s 0.74%. These factors include different demographics, for example the number of elderly in a population, as well as how deaths are reported. For example, in some countries everybody who dies after having been diagnosed with COVID-19 is recorded as a COVID-19 death, even if the disease was not the actual cause, while other people may die from the virus without actually having been diagnosed with COVID-19.
However, the models fail to incorporate explicit causal explanations in their modelling that might enable us to make more meaningful inferences from the available data, including data on virus testing.
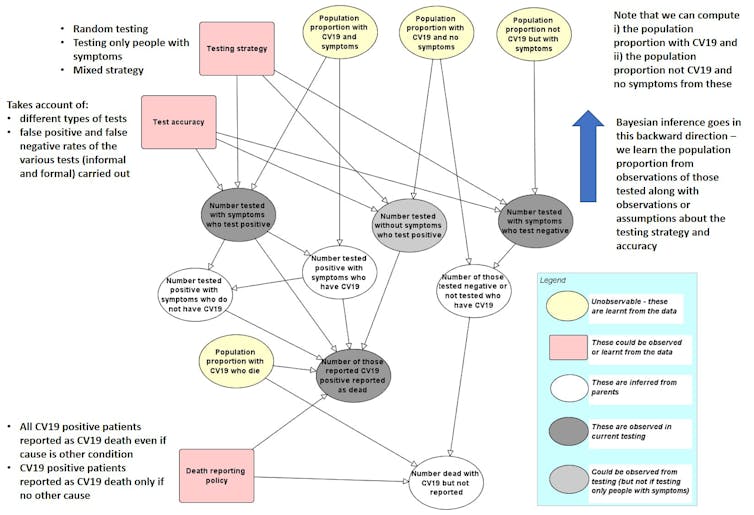
What a causal model would look like.Author provided
We have developed an initial prototype “causal model” whose structure is shown in the figure above. The links between the named variables in a model like this show how they are dependent on each other. These links, along with other unknown variables, are captured as probabilities. As data are entered for specific, known variables, all of the unknown variable probabilities are updated using a method called Bayesian inference. The model shows that the COVID-19 death rate is as much a function of sampling methods, testing and reporting, as it is determined by the underlying rate of infection in a vulnerable population.
Therefore, different countries may appear to have different death rates, but only because they have applied different sampling and reporting policies. It is not necessarily because they are managing the virus any better or that the virus has infected fewer or more people.
With a causal model that explains the process by which the data is generated, we can better account for these differences between countries. We can also more accurately learn the underlying true population infection and death rates from the observed data. Such a model could be extended to include demographic factors, as well as social distancing and other prevention policies. We have developed such models for many similar problems and are currently gathering data required for populating the kind of model that we outline in the above figure.
Random testing
In the absence of community-wide testing, only random testing applied throughout the population will enable us to learn about the number of people with COVID-19 who are asymptomatic or have already recovered. Only when we know how many people don’t show symptoms, will we know the underlying infection and death rate. It will also enable us to learn about the accuracy of the tests (false positive and false negative rates).
Random testing therefore remains the most effective strategy to avoid selection bias and reduce the distortions in reported statistics. Ideally, this should be combined with a causal model.
Random testing would be ideal.SamaraHeisz5/Shutterstock
Currently it seems there are no state-wide protocols in place in any country for randomised community testing of citizens for COVID-19. Spain did attempt it. But that involved purchasing large volumes of rapid COVID-19 tests, and they soon discovered that some Chinese-sourced tests had poor validity and reliability delivering only 30% accuracy – resulting in high numbers of false positives.
Read more:
COVID-19 tests: how they work and what's in development
Countries like Norway have proposed introducing such tests, but there is uncertainty around how to legislatively compel citizens to test – and what might constitute an appropriate randomisation protocol. In Iceland, they have voluntary sampling which has covered 3% of the population, but this isn’t random. Some countries with large scale testing, like South Korea, might get closer to being random.
The reason it is so hard to achieve random testing is that you have to account for several practical and psychological factors. How does one collect samples randomly? Gathering samples from volunteers may not be sufficient as it does not prevent self-selection bias.
During the H1N1 influenza pandemic of 2009–2010, there was a lot of anxiety about the disease that created “mass psychogenic illness”. This is when hypersensitivity to particular symptoms leads to healthy people self-diagnosing as having a virus – meaning they would be highly incentivised to get tested. This could, in part, further contribute to false positive rates if the sensitivity and specificity of the tests are not fully understood.
While self-selection bias is not going to be eliminated, it could be reduced by running field tests. This could involve asking the public to volunteer samples in locations where, even in a lockdown state, they might be expected to attend and also from those in self-imposed isolation or quarantine.
In any event, it is important to note that when statistics are communicated at press conferences or in the media, it is very important that their limitations are explained and any relevance to the individual or population are properly delineated. It is this which we contend is lacking in the current crisis.